This is the third article in the series on What should you log in an application and how to avoid having 24×7 support looking at them? In the previous article we talked about how to setup Elastic Search and Kibana, in this article we’ll learn how to properly send logs from your application servers to Elastic search and do some processing in between and after we are done, we’ll have a system ready which can handle terrabytes of log data with rare human intervention requirements.
So… what is this Kinesis thingie?
Kinesis is an AWS data streaming service whose job is to deliver data reliably from one end to the other while adding extensions so as to make processing data easy and scalable. It is divided into two main sub-products:
- Kinesis Streams: Open ended data streams where you have data producers and consumers, you can define your own data consumers, this one does not scale on its own and you have to define the number of shards (capacity) you want from it beforehand.
- Kinesis Firehose: This is same as above with the difference that it scales automatically and although data producers can be anything, data consumers are pre-defined, at the time of writing the article, valid consumers were:a. Amazon S3b. Amazon Elastic Search servicec. Amazon Redshiftd. Amazon Kinesis Analytics service
Because we don’t want to worry about scaling and are interested in putting the data in AWS ES service anyway, we are going to go with Kinesis Firehose. If there is still some confusion about what this is for, it will get cleared up as we try setting stuff up below.
Why Kinesis? Why not simply send stuff to Elastic Search directly?
Pt#1: Because logs also contain blobs
Typically logs contains exception logs, server events, application events (Trace, debug info’s and request/responses) all these are necessary for good analysis of your data and is key to correctly and swiftly analyzing log data for diagnostic or analytical purposes. Now log lines (line = 1 entry of whatever type) which contains potentially huge chunks of unstructured data like request/responses which is never really searched upon and only looked at for diagnosing bugs, are actually increasing the packet size of what Elastic search is crunching across nodes. Even if the field is marked for no indexing (see here for ES options on field indexing) the data will still play a role in cluster health in the following scenarios:
- Shard redistribution (common) happens when you add a node to ES, or a node goes offline and replica shards get activated and the load gets redistributed across nodes for balancing, when the node comes back up the redistribution will begin again causing cascading failures (shudder) in case the size of the shards are too large
- Shard resizing (less often), happens when you change the number of shards for an index
- The Node coordinating the search result across various shards across different machines needs to collate large amounts of data size-wise in order to return the merged result, this is very resource intensive and may cause intermittent node outage, resulting in shard redistribution which again might cause the same thing due to large shard sizes, cascading failure is back!
The only way to get away from the above stated problems would therefore be to throw GB’s of more RAM and storage coupled with double digit ethernet bandwidth with double the required nodes, if you shuddered at the thought of this statement then no, don’t just store everything on ES.
Pt#2: Because lots of logs are unprocessed
Logs, a lot of times are unprocessed e.g. you might want to add geographical data (lat/long) to the user IP address that you collected (imagine heat maps in Kibana), server events which are just text lines and cannot be searched upon (you want to convert these to JSON with readable attributes before you shove it in ES), lots of other things. What you don’t want to do is do these processings on your web servers. Web server’s primary responsibility is to serve your customers the best and as fast as they can, doing these resource intensive work on each of your servers and subsequently making sure that all your services which make up your application are following the same standard is just not worth it.
A good log data pipeline makes sure you have a scalable way to process these logs before they reach your log database so that your web servers are not effected while at the same time you have good searchable data that you can build amazing, actionable dashboards and alarms from.
Hmm.. ok.. then what should I be storing in ES now?
Elastic search as its name implies is brilliant at searching and even aggregating results across a humongous dataset while giving you near perfect horizontal scalability, use it to store fields that you search upon, aggregate upon. If you need to search for something in the request or response, you should be taking out that value and putting that in a separate field.
Ok, I’ll buy that, where do you suppose I put unstructured data in then?
Unstructured blobs (generally request/responses) should be put in storage optimized for large blob storage, which are essentially disks, in the AWS world, you have two options S3 (http based file storage) and EFS (made for cloud, network drive). In this article, I’ll be using S3 as the blob storage mechanism, simply because its easier to integrate and has easy auto-archiving strategies.
In this guide we’ll send the request/response through Kinesis and just before stuff gets into Elastic search we’ll have Lambda functions massaging the log data, take out the blobs, put them into S3 and replace the log lines with clickable S3 links instead.
Are there any limitations to Kinesis?
While I would love to say that Kinesis is the anti-Gandalf and anything can pass through, it does have the following limitations:
- The maximum size of a record sent to Firehose, before base64-encoding, is 1000 KB (you can compress your request/response to meet this requirement)
- The PutRecordBatch (bulk insert into the stream) operation can take up to 500 records per call or 4 MB per call, whichever is smaller. This limit cannot be changed
- Data is buffered for a minimum of 60 seconds or 1 MB (whichever is hit first), which basically means if you don’t have enough data going through the stream you might have to wait for a minute for your records to show up, this might be irritating in development environments, for production this is fine
There are other AWS account related limitations which are worth noting, here is a link to AWS documentation for the complete set of Kinesis limitations, quite a few of these limitations can be increased by a simple support ticket to AWS via the console.
Enough talk, Let’s setup the log data pipeline already!
Setting up Elastic search
I have the elastic search (5.1) already setup using AWS Elastic search service, see this article where I take you step by step in how to do that.
Setting up a index template for time-based log indexes
Now if you went through the above mentioned article to setup your ES you already know that you should have time-based indexes for logging in ES, however, in order to control the behavior of these auto-generated time based indexes you can put index templates in ES so that whenever a new index is created for the day/week/month etc it automatically inherits the traits from the template that we define.
We will define 4 shards per index and one replica since in the test setup we have only one elastic search node, you might want to have at least 2 replica’s in production.
PUT _template/active-logs
{
"template": "active-logs-*",
"settings": {
"number_of_shards": 4,
"number_of_replicas": 1
}
}
There is a maintenance overhead for shards so you don’t want too many shards for an index however you also don’t want gargantuan shards which would overload a node’s resources while aggregating/transferring/replicating etc.
Getting Lambda methods to intercept the log data and slicing blobs into S3
We will transform and put the request and response in a S3 bucket as discussed before, create the lambda function exactly as I demonstrated in this post and swap the program.cs file with this:
using System;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
using Amazon.S3;
using Amazon.S3.Model;
namespace CSharpLambdaFunction
{
public class LambdaHandler
{
public static void Main()
{
Task.Run(async () =>
{
Stream result;
using (var stream = new FileStream($"{Directory.GetCurrentDirectory()}\\testData.json", FileMode.Open))
{
result = await new LambdaHandler().LogHandler(stream);
}
using (var reader = new StreamReader(result))
{
var records = reader.ReadToEnd();
Console.WriteLine(records);
}
}).GetAwaiter().GetResult();
}
public async Task LogHandler(Stream inputStream)
{
LogEntry entry;
FirehoseInput input;
using (var reader = new StreamReader(inputStream))
{
input = Deserialize(reader);
}
foreach (var record in input.records)
{
record.result = "Ok";
using (var memStream = new MemoryStream(Convert.FromBase64String(record.data)))
{
using (var reader = new StreamReader(memStream))
{
entry = Deserialize(reader);
}
}
var reqTask = SendToS3AndGetLink(entry.Request);
var resTask = SendToS3AndGetLink(entry.Response);
entry.Request = await reqTask;
entry.Response = await resTask;
var data = ConvertToStream(entry);
record.data = Convert.ToBase64String(data.ToArray());
}
return ConvertToStream(input);
}
private T Deserialize(TextReader reader)
{
var serializer = new Newtonsoft.Json.JsonSerializer();
return (T)serializer.Deserialize(reader, typeof(T));
}
private MemoryStream ConvertToStream(T logEntry)
{
var serializer = new Newtonsoft.Json.JsonSerializer();
var memStream = new MemoryStream();
var writer = new StreamWriter(memStream);
serializer.Serialize(writer, logEntry);
writer.Flush();
memStream.Position = 0;
return memStream;
}
private Stream ConvertToStream(string value)
{
var memStream = new MemoryStream();
var writer = new StreamWriter(memStream);
writer.Write(value);
writer.Flush();
return memStream;
}
private async Task SendToS3AndGetLink(string value)
{
var s3 = new AmazonS3Client(Amazon.RegionEndpoint.USWest2); //define your own region here
var putRequest = new PutObjectRequest();
var key = Guid.NewGuid().ToString().Replace("-", string.Empty);
putRequest.BucketName = GetBucketName();
putRequest.Key = key;
putRequest.InputStream = ConvertToStream(value);
putRequest.ContentType = "application/json";
var response = await s3.PutObjectAsync(putRequest);
var urlRequest = new GetPreSignedUrlRequest();
urlRequest.BucketName = GetBucketName();
urlRequest.Expires = DateTime.UtcNow.AddYears(2);
urlRequest.Key = key;
return s3.GetPreSignedURL(urlRequest);
}
private string GetBucketName()
{
return "cloudncode-logs";
}
}
public class FirehoseInput
{
public string invocationId { get; set; }
public string deliveryStreamArn { get; set; }
public string region { get; set; }
public List records { get; set; }
}
public class FirehoseRecord
{
public string recordId { get; set; }
public string result { get; set; }
public string data { get; set; }
}
public class LogEntry
{
public string RequestId { get; set; }
public string SessionId { get; set; }
public string Timestamp { get; set; }
public string UserId { get; set; }
public string ServerIp { get; set; }
public string Message { get; set; }
public string Level { get; set; }
public string Category { get; set; }
public string Request { get; set; }
public string Response { get; set; }
}
}
if you don’t want to learn how to do that right now, you can also choose to download the source code directly from here, but you will need Visual Studio Code to compile and run it. If you are simply downloading the source code, go the article I mentioned above and start from “Step 6: Add AWS users and roles”.
Note that the source code here is slightly different, the Lambda article that I wrote talks about a general Lambda function, however, Kinesis firehose gives a specific input and expects a specific output for the transformation to work. For our general knowledge, here is what Kinesis firehose gives as input to our Lambda function:
{
"invocationId" : "cd6eb022-9528-42c6-82fb-e5e969ea7962",
"deliveryStreamArn" : "arn:aws:firehose:us-west-2:522390xxx:deliverystream/logstream",
"region" : "us-west-2",
"records" : [{
"recordId" : "49570122502395591010539641575388588252247858295703863298",
"approximateArrivalTimestamp" : 1486135421633,
"data" : ""
}
]
}
And here is the output that it expects:
{
"invocationId": "cd6eb022-9528-42c6-82fb-e5e969ea7962",
"deliveryStreamArn": "arn:aws:firehose:us-west-2:522390xxx:deliverystream/logstream",
"region": "us-west-2",
"records": [
{
"recordId": "49570122502395591010539641575388588252247858295703863298",
"result": "Ok", //Valid options are "Ok", "Dropped" & "ProcessingFailed"
"data": ""
}
]
}
In the record.result field in the output above stating Dropped marks the result to be successful and indicates that the stream should stop further processing of the object and not send it any further.
Visualizing Kinesis Data Flow
Before we move further and create the actual data stream, let’s make sure we have a picture in mind on how the Kinesis data stream flows from the origin (app servers/devices) to the destination which is Elasticsearch in our case.
Consider the diagram below:
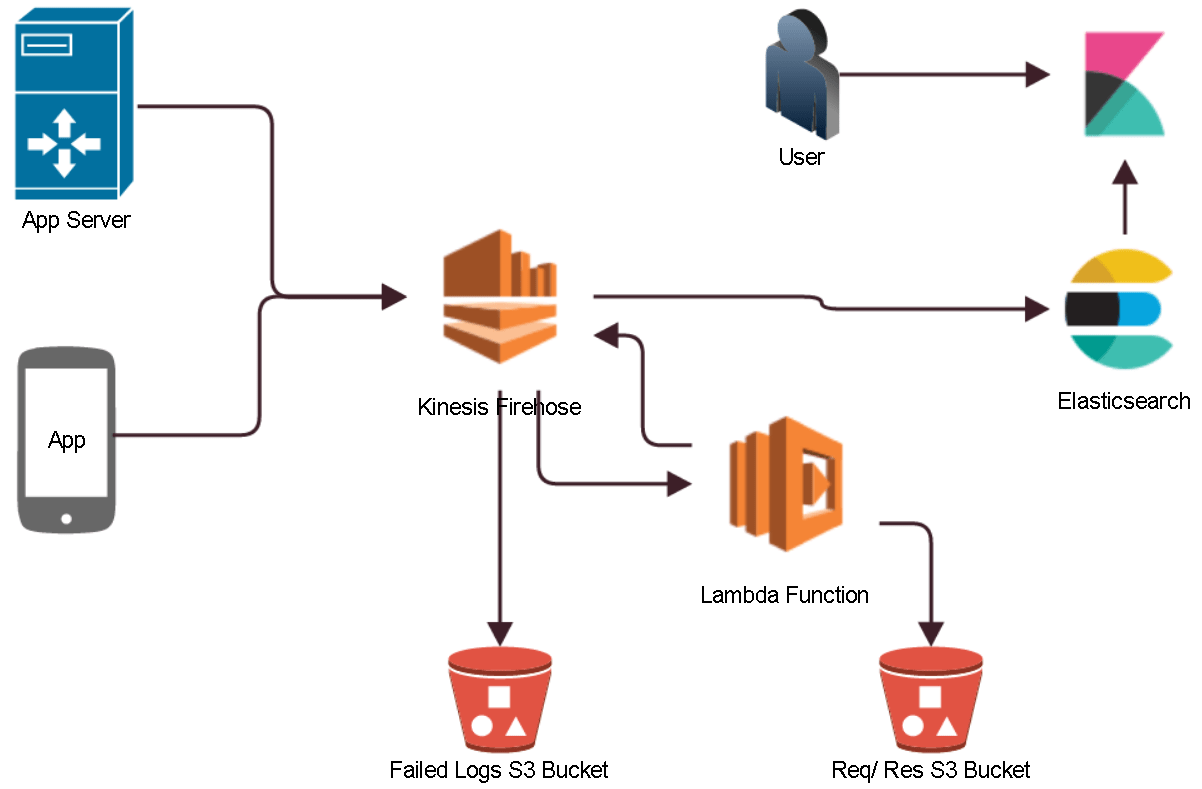
- Kinesis receives data from your app server or directly via a smartphone app
- The data stream invokes a Lambda function which takes out request and response and decompresses the incoming log if it was compressed from the origin (in our case for simplicity’s sake, we won’t compress it) and puts them in an S3 bucket and further proceeds to replace the same with URL’s which the Kibana users can click on later to view the req/res in their browsers
- Lambda then returns the transformed log back to Kinesis which then puts them into the AWS Elasticsearch service
- In case any logs fail and all retries fail (retries are configurable), the failed logs are put in a configurable S3 bucket which can then be processed seperately, note that you can also dump every log into an S3 bucket along with the Elasticsearch service, however unless you mind not getting a fat bill from AWS I would dissuade against that
- Logs can then be viewed by the user using Kibana
Setting up Kinesis Firehose
Go to AWS Kinesis service page and then select Kinesis Firehose as the type of data stream, proceed to click on “Create Delivery Stream” as shown below:

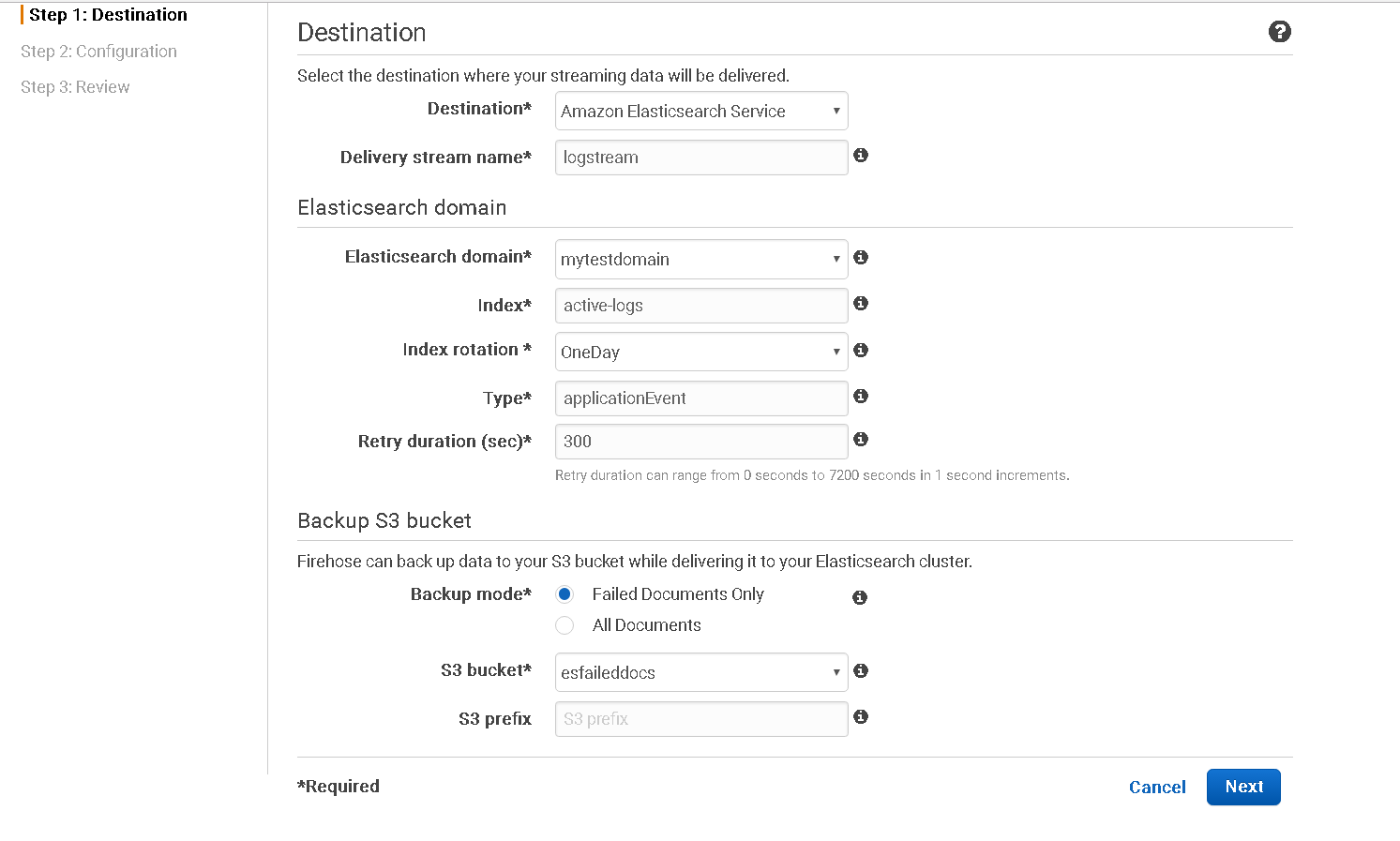
We want the data stream (Kinesis firehose) to send the data to our already setup AWS Elastic Search service, follow these steps:
- Choose Amazon Elasticsearch Service in the destination dropdown
- Give your stream a name, remember it will contain log data
- Choose your ES domain and type in
active-logsin the index textbox, this name must correspond to the temaplate pattern that we had setup earlier - Choose index rotation to OneDay, you can choose something different here as well depending upon the amount of traffic that you normally get in a day. A day is a safe choice if you are confused
- Put in
applicationEventin the type, this is the ES type in the index that will hold the documents, we want this stream to put in application events for now - Setup to choose to backup your failed documents in S3, you can choose the safer option to backup everything as well, remember S3 charges per PUT request, this is more of a what you can afford to do kind of a question
- Create a new S3 bucket here, the dropdown will guide on doing the same
- Click on
Next
In this step, we’ll configure our data stream to use the Lambda function that we had created earlier which will take away the request and responses and replace them with Url’s, simple steps here, just refer the image in case you get confused.

- Setup the
buffer sizeto be5MBandintervalto be60 seconds, basically Kinesis will collect and send in logs together to ES for efficiency sake and will do that as soon as any one of the two conditions are fulfilled, i.e. either the collected documents reach 5MB in size or 60 seconds have elapsed since the documents had started to get collected. - Since the backup S3 bucket only contains failures, you don’t need compression here, you should compress docs if you are backing up everything to S3 though
- Leave the S3 data unencrypted, I prefer controlling access to S3 instead, makes life simpler
Keeptheerror logging enabled, it will help us in diagnosing any issues with our data stream- Create an
IAM rolefor your stream which will give it access to send backups to S3, invoke the Lambda function and put documents into ES, when you select “Create a new role” from the dropdown it guides you in creating the role with just enough permissions to get the stream to work - Click on
Next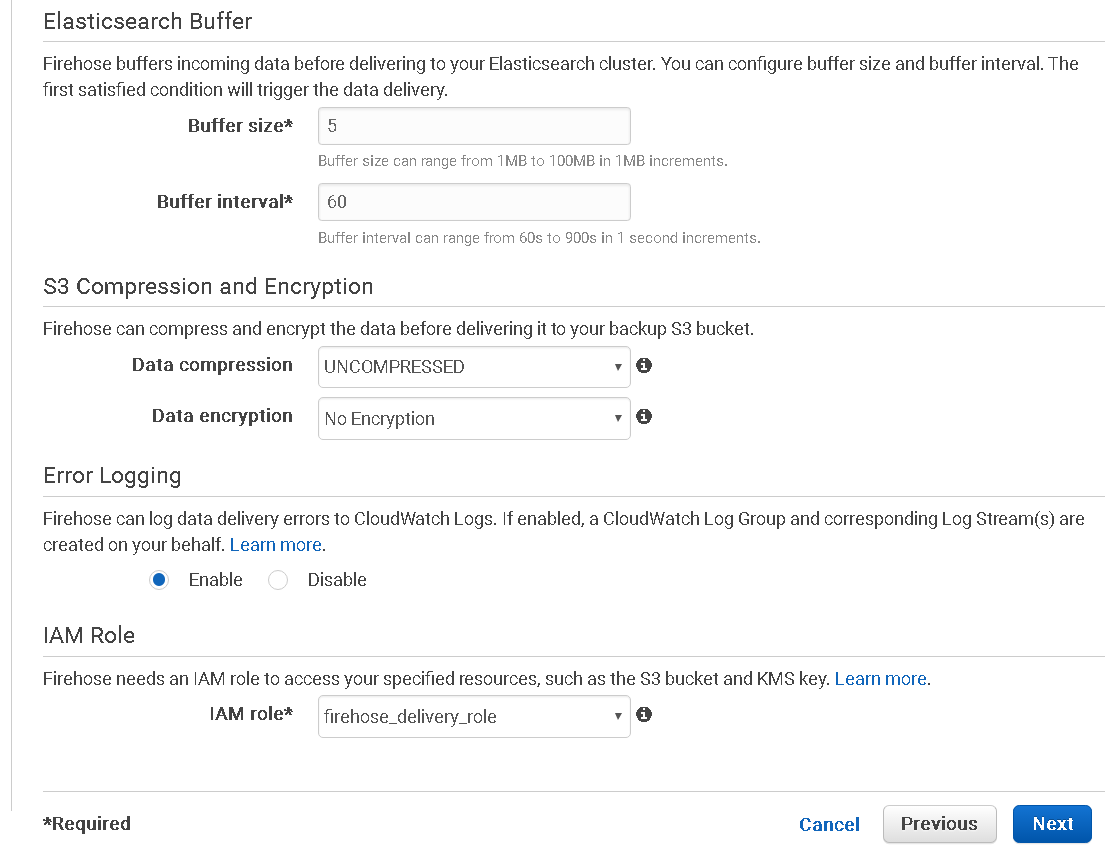
Sending data to Kinesis
Logs can be sent to Kinesis via a Kinesis agent or via the AWS SDK, the agent although a pretty good option is currently available only for Amazon Linux AMI with version 2015.09 or later, or Red Hat Enterprise Linux version 7 or later. The agent basically picks up files from your server and transmits them to Kinesis completely decoupling your app from Kinesis. To know more about this option go to this AWS documentation.
If you will be sending data via the AWS SDK from either a app server or a end-user device such as a smartphone you can check out the AWS documentation link for the same or you can download a simple utility that I built to quickly test things out, here is the source code for a sample tool that I made in dotnet core using Visual Studio Code, when you have the code opened, you can just change the testData.json file and put in whatever log request you want and run it. As always, change the region name in the code and make sure your AWS credentials file (C:\Users\\.aws\credentials for windows) contains valid credentials with permissions to send data to Kinesis. If you don’t have these credentials configured, you can learn how to do that from this link at AWS site which covers other operating systems apart from windows as well.
Seeing the results on Elastic search (through Kibana)
At this point you should have:
- A running AWS Elastic search service with templates added for our indexes which will be created via Kinesis firehose
- A Lambda function which we will use to transform our logs and related S3 bucket where the request and responses will be moved into
- Kinesis Firehose all setup to receive data from the servers/devices
- Some test data inserted into Elastic search
Now we will setup Kibana with a simple table example so that users can actually look at the logs that go into the system for analysis and action.
Open Kibana, as a refresher you can find the URL from the same from your Elasticsearch AWS console page, refer image below:

We need to add our index pattern into Kibana so that it knows that it needs to read the same, go to the management tab in Kibana and click on Index Patterns

Click on Add New
Put in active-logs-* in the index pattern box, The ‘*’ here denotes that as new indexes are created based on time they will all be included in the search that you make, then proceed to click on Create.
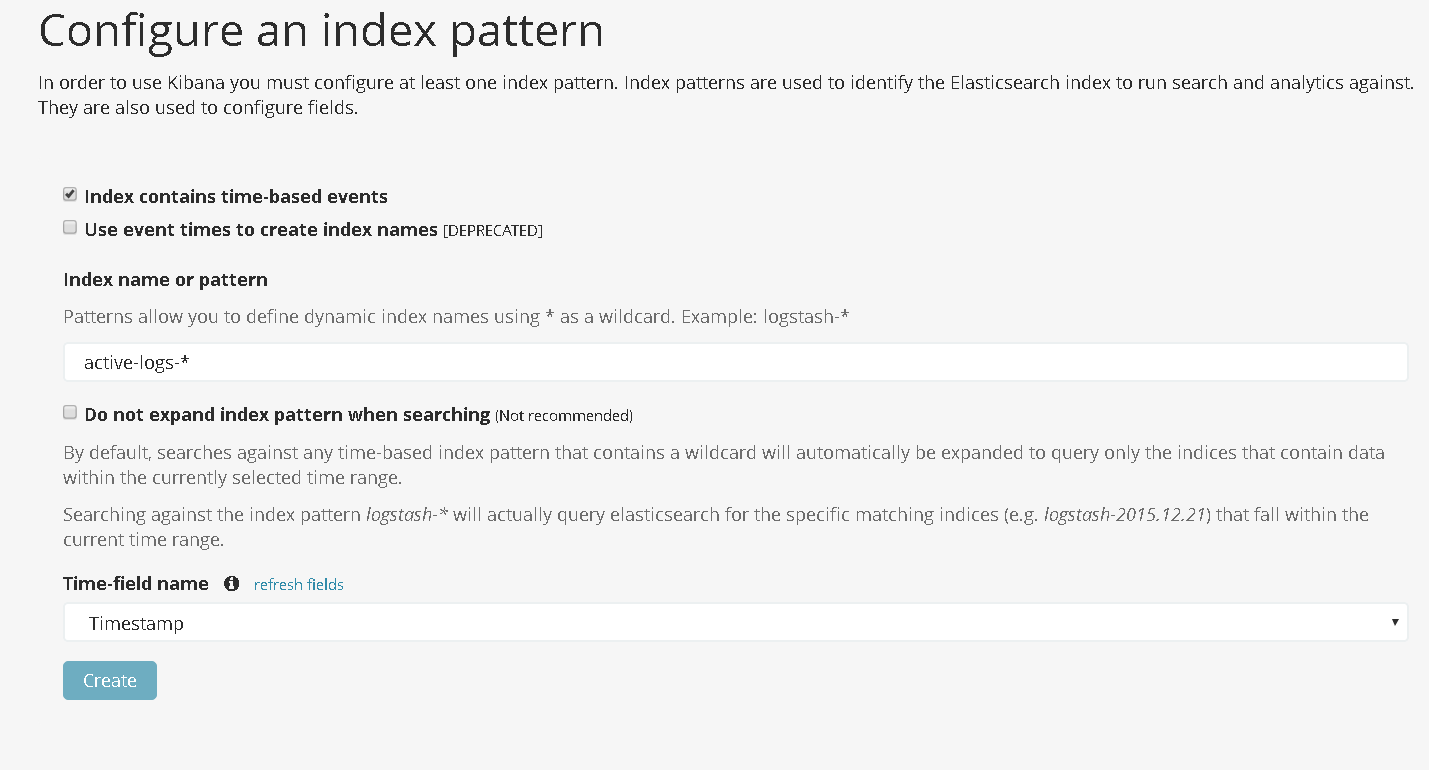
After the index is created, set it as default, this is optional of course, but as I had another index created while I wrote the ‘How to setup Elasticsearch’ post, I didn’t want that to be my default.

Go to the Discover tab and change your index to the correct one if not already (refer image), in case you don’t see your test data as shown in the image try changing the time from the top-right corner in case the data was added in the past as in my case, click on Save and fill in name for the query.

Now we will add a dashboard where we will save add the data table which users can later come and look at.
Go to the Dashboard tab, click on Add and go to the Saved Search tab in the Add Panels section. Here you should see the query that you had saved before, select that.
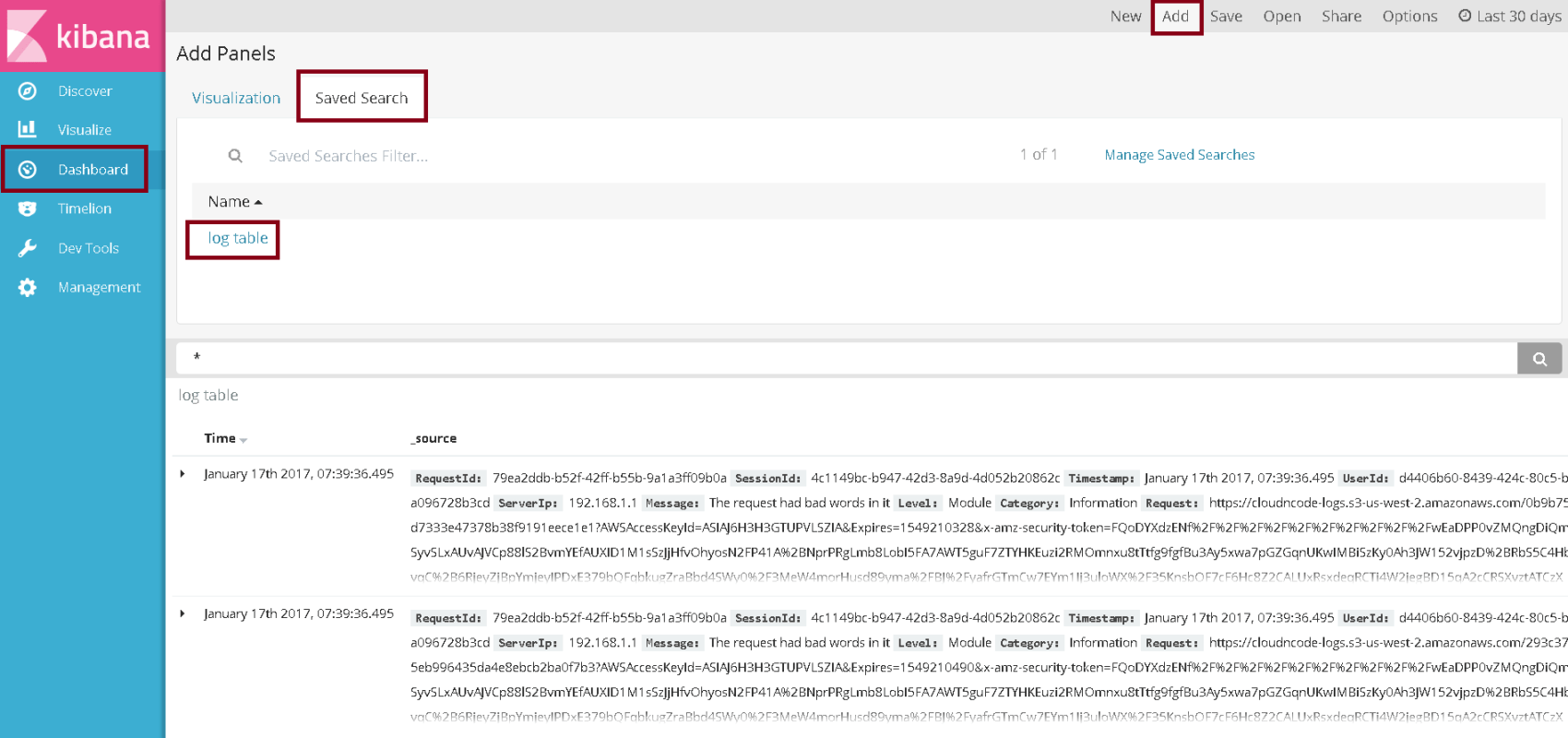
To save this dashboard, click on the Save button from the top bar, give your dashboard a name and proceed to click on Save.

There you have it folks, users can now come to Kibana, look at logs, you can also setup other graphs like errors over time, user hits according to time of day or whatever you can think of.
Short note on S3 storage mechanisms, archival options
S3 is a highly reliable redundant object storage service from AWS, along with simply providing space to store files, you can also:
- Manage security/access
- Setup events which can invoke Lambda functions to take some action (move data, setup alerts, send stuff into other databases/ queues for further processing etc)
- Manage archival of data by either deletion or moving to cheaper storage options like AWS Glacier
If you want me to write on any of these topics specifically, let me know by commenting below.
What’s left to get to the point where I will no longer need 24×7 support?
Now that we know what to log, how to get elastic search and kibana up to view the logs and how to get data properly into elastic search using AWS Lambda to utilize S3 as blob storage, we need to now learn how to have:
- SNS integration with Pagerduty / emails for real-time alerts which
rings your phone for severity 1 issues - Backup monitoring to monitor Elastic search to build a fool proof auto-alert system in case the primary alert mechanism begins to fail
Follow this blog/subscribe to email alerts (top of sidebar or below comments in mobile) so that you know when any of these posts come about.













Pingback: Scaling for TB level log data with Kinesis Firehose and lambda with Elastic Search on AWS | Ace Infoway
Pingback: What should you log in an application and how to avoid having 24×7 support looking at them? | cloudncode
I don’t understand. You’re saying “you don’t need everything or unprocessed logs inside ES”, but as far as I understant, Kinesis is just your “broker” and will ship everything into ES… right ?
LikeLike
Sorry, in fact the Lambda function could be extended to filter some logs…
LikeLiked by 1 person