Just to refresh our memories, micro service architecture is an evolution of the SOA architecture, whereas SOA was focused on integration of various applications, Micro services architecture (MSA) aims to create small modular services which belong to a single application.
MSA came to the forefront with the advent of high speed computing (lowered latencies) and the continuously growing need of continuous deployment and integration.
One other major advantage with MSA and often overlooked is that now independent services can be written and re-written in different languages which is best suited for the service, or just because it has too much bloat which would otherwise spark off a multi-year re-write project… and we all know where that leads us.
Wait…what has CI or CD to do with MSA?
With MSA as we inherently get modular services broken by functionality, we can make changes inside one and deploy it with peace of mind knowing that it will not effect any other service as long as the external interface (API contract) is not modified. The latter fact allows us to scale, lower significantly the time to production (lower scope of testing) and fail fast.
MSA issues and resolutions
If this is the first time you are building an application with MSA or contemplating building one or just curious, these are the things I watch out for. Note that the list given below is limited by my experience and is not meant to be a comprehensive list, I will keep updating this list as I learn more and do give comments at the bottom as to what I have missed. Note that this article is meant as a starting point to discover what all is involved, for each individual topic extensive research is what I will recommend.
Nano-services
When building an application through MSA, it is a common problem to get carried away and make the services simply too small, so small that the overhead and complexities of so many services begin to outweigh the benefits, such services are known as nano-services… so yes, they are a bad thing. Services should be broken down by functionality verticals such as billing, payments, booking etc, if you have independent services like “GetUser” and “GetUserById”, you have gone straight down to nano-service hell. Extreme examples are of course a tool to get an understanding, real-world nano-services are subjective to the functionality of the application….. however, objective henceforth.
Its hard to keep track of the service URL’s
When there are too many services maintaining the configuration for their individual addresses becomes harrowing, especially since addresses change with environments, for misc infra reasons etc. Now you might use a load balancer and a proxy like HAproxy to centralize this, I have done this myself for simplicity, however, a load balancer is just another layer to add its own latency, failure point, the need to effectively manage DNS switches based on geography if you have a multi-region deployment (multiple data centers) etc.
So what can you do if you don’t like load balancers? You can use a concept popularly known as “Service Discovery”. In this concept services which start up register themselves with a central authority with some basic parameters such as environment & application name in case multiple environments share the same infrastructure and the applications which wishes to connect with them polls the one service asking a connection against the app name and environment name etc. This software in turn then can also ensure basic load balancing like round robin to load balance in case multiple services registered themselves with the same parameters, effectively enabling direct communication. Look at the picture below for an illustration of the same.

The first question that arises is… so we replaced the latency of the load balancer by the service discovery program… fair comment… however generally speaking these softwares generally reside in the same machine as the service so as to inherently scale and be performant, moreover since the data passed between them is fairly rudimentary they use faster protocols and are generally DNS queries.
Note that the load balancer technique is also known as “Server side discovery” and what we are talking about here is also know as “Client side discovery”.
Advantages & Disadvantages
Everything in the software world is subjective out of context of the specific use case, consider the advantages and disadvantages before you choose any model, the article seemed skewed towards client side discovery only because it is lesser known and fits in a variety of use cases.
Advantages
- Client side service discovery or just service discovery reduces network hops and increases the overall performance of the system.
- The above also mitigates the need of a highly available and performant load balancer system, if however you are in the cloud, this is generally cheaply available e.g. AWS ELB.
Disadvantages
- Yet another software to learn (Eureka/Consul .. whatever).
- This couples the client with the service registry, using something like Zuul (like a proxy) negates this issue, however removes the performance benefit at the same time.
- You have to make sure that the registry has client side code in all languages / frameworks that you build your services in.
People have issues in discovering services, the available API’s & writing & maintaining clients
With MSA, one implied complexity that gets introduced in the system is well, a lot of services. If we don’t document these services well and let’s not kid ourselves we won’t, numerous issues arise over time, some of them that I have noticed are:
- With lack of documentation a team implementing service X which should be using service of team Y has unnecessary overheads of communication, general mistakes and in general bitching as to why team Y doesn’t care enough about their deadlines.
- No documented contract of the service means a central person/group cannot make sure that all the API’s follow a particular standard, leading to each team or even the same team developing different looking API contracts.
- Every time a service is being called in another service plumbing code needs to be written to integrate with the service, including models, connectors etc, if you are one of those super organized teams which churn out clients after every time a service is built for every language that other teams uses, then rule this statement out.
- Every time a contract changes slightly every team needs to be informed about the new functionality and the plumbing code needs to be updated.
- Every time an automation QA guy needs to understand the 20 services that you have he will need to sit with the relevant team to understand or force them to make a document for him, this will repeat with changes to the contract.
- For those services which are public in nature, the documentation’s test harness or try it functionality (which you should have) is always lagging from the actual service contract.
I am very opinionated on this one, sometimes there is one clear best solution for the problem (at the time of writing this article anyway). Use Open API (https://openapis.org/), it is:
- A collaborative initiative under the Linux Foundation
- Vendor / Language neutral
- Defines specifications for REST services with JSON and XML formats currently with more in the offing.
- Standardized specification aims to build a community of tools for the API eco-system.
- Has members like Google, Microsoft, IBM, APIgee, Atlassian among other notable ones, see the project website for the complete and current list.
Open API was started in November 2015 and has already seen large adaptation, at the time of writing this article it was witnessing 15000 downloads per day.
Since the initiative started from SmartBear donating the Swagger specification to the organization, Swagger then evolved from 1.0 to 2.0 as not just an automated documentation tool, to a standard way of defining a RESTful API. The latter fact also implied that Swagger 2.0 (or whatever is current) is the best place to start this.
You can adapt Open API to your project generally in under a day with full specifications of all existing API’s up and running and usually no iterative work going further.
Integrating Swagger 2 basically means getting the specifications of your API’s in a standard format very similar to what WSDL used to be, except this one is vendor & technology agnostic. As the specification is standard, it opens of worl of tools built by the community and enterprises alike which automates auto-doc UI with try it features (works with custom authentication with a few tweaks), generating client SDK via command-line in dozens of formats, generating JMeter plumbing code, integration with some API gateways like APIgee or AWS API gateway and much more, check out Swagger @ http://swagger.io/.
Here are some references to get you started on this one:
Open API Introduction https://openapis.org/
Swagger Website http://swagger.io/
Infra services that support Swagger https://github.com/OAI/OpenAPI-Specification/wiki/Sites-and-Services
Swagger 2.0 Specifications https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md
Tools & Integrations http://swagger.io/open-source-integrations/
Swashbuckle for .Net Swagger integration https://github.com/domaindrivendev/Swashbuckle
AutoRest for .Net SDK generation from Swagger spec https://github.com/Azure/AutoRest
Swagger-Codegen for Java, php etc SDK generation https://github.com/swagger-api/swagger-codegen
Too many deployment jobs
This is an inherent issue of having multiple services, I wish I could tell you that some software will solve this, unfortunately though, you can’t escape this one. What you can do though is use deployment tools that make your life easier, my ever-green favorite remains to be Jenkins @ http://jenkins.io (use base templates to make writing new jobs easier), there is beanstalk which is some people’s favorite @ http://beanstalkapp.com.
One service connection fails, everything fails
With the spider web of all the services to work with, chances of failures increases, and handling them becomes more complex, well, more complex than calling a method in a class anyway. Fortunately, MSA is not a new thing and there are well defined and tried and tested methodologies to work with the complexities. Some of things that you must have while connecting to other services:
Retries
The simplest one first, have retry logic in your service calling code in case the first call fails, maybe its just one service which is running faulty and the second one will wind up connecting to another load balanced server or whatever else, keep these points in mind:
- Retry a fixed number of times :).
- Limit the service timeout across retries, don’t let individual tries use the total timeout defined.
- Do an exponential backoff between tries, e.g. immediate first try, sleep for 10ms for 2nd try, 50ms for 3rd try, fail. This will ensure that services don’t start bombarding a recovering service with retries and failing the service in a cyclic fashion.
Circuit-breaker pattern
Unlike in-memory calls, service calls have an issue wherein the response is rather more undeterministic, the response might take a long time to come back, hang forever or just return errors. In this scenario what happens sometimes is that the calling service if it waits for timeouts to occur it will start using up system resources such as available connections, threads etc and will respond slower to its own caller causing a cascading effect of disaster where every service slows down and in high traffic situations might just begin to fail in a cascaded manner.
To avoid the above situation, circuit breaker pattern is generally used. The circuit breaker pattern is rather simple, in the pattern the code keeps a counter of what is happening to any particular service and if a threshold number of errors have been continuously returned by the service, it “opens” the circuit and fails fast all the subsequent requests to the same service for a predetermined amount of time thereby giving the errant service time to recover rather than bombarding it with more messages preventing it from healing itself again usually by standing up more servers and warming up.

Apart from “Closed” state (allow everything to pass through, watch and count errors) and “Open” state (fail everything immediately until a preset time), a third state “Half-Open” occurs after enough time is spent in the open state. In the half-open state the circuit lets limited traffic through to test the waters, if the response comes back healthy then the circuit is closed and traffic starts to flow through, if it fails, the circuit is opened again. The latter is done so as to make sure that a recovering service is not flooded with requests immediately as it starts responding.
In Java Hysterix part of Netflix OSS is a popular choice @ https://github.com/Netflix/Hystrix
In .Net try Akka.Net @ http://getakka.net/ (its part of the utilities).
Database isolation
One of the motivations to write one big article trying to cover everything at a higher level is to keep the perspective intact. More often than not when we are adapting something new, we tend to compromise with something or the other, database being its biggest victim.
While selecting the MSA the primary benefit to keep in mind is to develop completely independent services which are self-contained, this implies that their storage technologies are self contained as well. There are three approaches to tackle this problem:
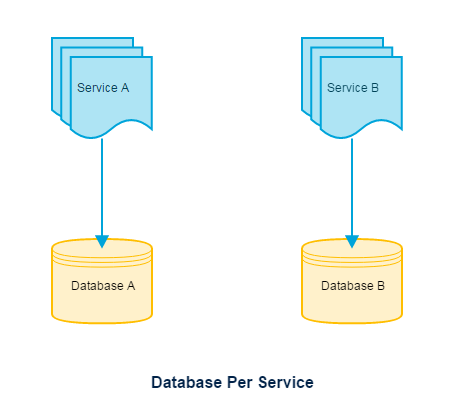
Database per service
The best answer, database per service allows each service to be independent, gets deployed independently, gets the power to choose a different persistence technology (e.g. Elastic search for searching) per service. Choose this by default.
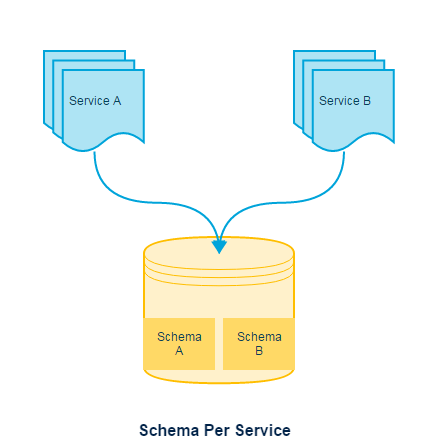
Schema per service
Something you can get away with, schema per service allows you to isolate data for each service clearly via schema and its easy to identify what belongs to which service.
Tables per service
One thing which is possible is that each service has its own dedicated set of tables and development processes keep services to use other service’s tables. In my opinion this is too hard to keep up to and by choosing this approach we are just kidding ourselves.
Wait, how will I group data which is cross-functional?
Query the service to get the data and interpolate the result into the usable form, that is what MSA is all about.
What about data warehousing?
If all databases are separate and all can be in different technologies, how do I get reports / analytics out?
Data warehousing should publish its own contracts and it should be the individual service’s responsibility to keep publishing data in the format that is expected without tying down the service’s database schema to something fixed. On popular method of getting such large scale data out there is via putting data events in a queue which wind up in the warehouse.
Every service has to support all the transport protocols & authentication
It is common to have a requirement for the services to support multiple transport protocols for various devices, AMQP & http being the most common, more so however, all services exposed to the internet must also support authentication and in a lot of cases authorization as well. Implementing this plumbing code in all the services is usually done via a common library to reduce development time, however that has multiple disadvantages that are not obvious at first (or at least it is not obvious the severity of the disadvantages):
- If there is a fix / enhancement in these common modules, or if you need to support another transport, you must then test and deploy all the services affected, which in most cases are all of them.
- One of the main advantages of MSA is that all these services are completely independent, which means that if the use case calls for another technology or if you want to shift to another technology piece by piece you will have to re-do the common modules and then make sure that all services authenticate / authorize in exactly the same way, your transport protocols to be always in sync with the version that each service supports e.g. http 1.0/1.1/2.0 or similar.
- You need to make sure that all your services are secure in a standard way when exposed to the internet.
To get rid of this problem the most common and popular way of resolving is via an API gateway, an API gateway is simply a proxy which is aware of the location of all your services registered with it and that takes care of supporting all the different protocols of communication in turn translating it to a common protocol understood by all your services, generally HTTP, but it can be whatever. This gateway also takes care of authentication and authorization, letting your actual services being inside a closed network with all the security related stuff centralized into the gateway itself.
The diagram below explains this in a better way:

Due to the demand for such a gateway, there are numerous SaaS offerings out there which do all of this for you, the market leader at the time of writing this article was Mashery @ http://www.mashery.com/api/gateway with APIgee being another popular supporting open API @ http://apigee.com/about/, for the AWS deployed solutions AWS API Gateway is another solution (supports Open API) @ https://aws.amazon.com/api-gateway/, the AWS offering however is relatively new but they are adding new features to it often enough, go for this if you use AWS as your public cloud provider.
Too many servers, too much cost
Yes and no, it is true that a monolith service would consume server resources more efficiently and will be easier to write deployment scripts for, however, where MSA really shines is the reduction of everyday costs for development and faster time to market by employing one time extra setup costs which is one of the major reasons to go for MSA to begin with.
The fundamental solution to this problem is to have good elasticity in scale, i.e. employ small machines (smaller the better) and just add more hardware as traffic starts rolling in and remove as it goes out, staying as close to the actual requirement as possible.
There are however quite a few ways to make the elasticity happen, but it depends where you are deploying and what type of application that you are building, I will discuss below the most popular one of these.
On-premise deployment / traditional IAAS service provider
If you are on-premise i.e. have your own data-center, or if you use a traditional IAAS service provider which takes weeks or days to allocate new servers, containers (read docker) is your best friend. Containers anyway make applications go faster if you can get rid of the hypervisor layer and allocating new docker containers is fast and is becoming a standard these days.
With containers you can estimate better as to the total hardware requirement that you will have, pad it, get it allocated, and then assign individual services more hardware from the available set on demand, while removing it as the demand goes away.
Public Cloud, like AWS, Azure….
If you are on cloud….welcome to the new world….. auto scaling is your best friend. If you are already here, chances are you know what I’m talking about anyway, for the uninitiated, you can add servers via images of the VM’s in a cloud and add or remove servers on the basis of whatever metrics / triggers to make sure that you have just enough hardware to cater to requests in a healthy way while paying by the hour/minute (depends on which cloud) for the resources that you consume.
Docker or any other container technology can also be used in public cloud of course, but since you generally can’t get rid of the hypervisor layer, container’s benefit in cloud is limited. Containers on cloud still makes sense for a hybrid cloud setup (some servers on-premises, some on cloud) to have uniformity across the board, but I can’t fathom anything else that would make sense.
Sporadically called services, in public cloud
In case your services are sporadically called, like no calls for half the day, absolutely mad in the morning, relatively quiet till evening, so on… You can go serverless… this means that if you combine an API gateway like AWS API gateway and lambda (http://docs.aws.amazon.com/lambda/latest/dg/welcome.html) you can actually not have any servers at all… where API gateway when it receives a call will invoke a lambda function spinning up hardware on-demand (in AWS I tested that it takes like ~27ms to do so) run the code necessary to cater to that request and then spins the hardware down. You pay by 100ms of usage, and you don’t have to maintain any hardware, OS, load balancers, anything at all.
Not the best choice for performance focused applications where every millisecond counts, but for everything else, its pretty awesome.
Summary
Learn about:
- Service Discovery (I recommend Consul, Eureka & Zuul combo are popular in the Java-Spring world).
- Open API standard for RESTful services, check out Swagger 2.0 @ http://www.swagger.io.
- Learn about API gateways, Mashery is industry leader at the time of writing this article, APIgee is another popular choice (works well with Open API), AWS API gateway if you have everything in AWS (will help you go serverless, also works with OpenAPI).
- Learn about circuit breaker pattern, Hysterix in the java world (Spring cloud)/ Akka.io, getAkka.net in the .Net world.
- Queues / Service bus for interacting between services (look at RabbitMQ, AWS SQS if using AWS, many others out there).
- Think whether you need to use the actor model instead, it adds complexity but is a good fit for some.
- If you have a large distributed system make sure you handle your logging well, checkout this article that I wrote on what you should be logging.
Disclaimer
The software’s that I have mentioned here are what I or the company that I worked at at some point decided to use them after weighing alternatives, it does not imply that XYZ software is not as good or even better than the ones I have mentioned.
P.S. Comment below if you want me to talk in detail about some topic and click on the Follow button at the top of the sidebar or below the comments section in mobile to get notified on future articles, cheers!




I have a remark about “One service connection fails, everything fails” : no it won’t. Or, at least, it shouldn’t .
One of the main reasons of having a MSA is that the resulting system must be resilient . If a microservice fails to start/becomes unreachable, the remaining ones should be able to gracefully handle this communication failure in such a way that the entire system is still usable.
Apart from that, nice guide ;)
LikeLike
Well, it’s hard to disagree with that statement, but I have seen that happen as quite a few times you cannot function without that one service (usually the one failing :) ), If possible though, yes, the system should be able to function.
LikeLike
I was surprised you didn’t mention event-driven architecture here. Isn’t that a core tenet of microservices?
LikeLike
Hmm… You are correct, although I mentioned it sporadically (data warehouse section) and the summary section, it did deserve a heading of its own.. Maybe I’ll come back and correct that mistake.
LikeLike
Pingback: What should you log in an application and how to avoid having 24×7 support looking at them? | cloudncode
Good article!
-For those who needs to get on track fast I recommend Microsoft Service Fabric (SF), a complete PaaS for all components (microservice, queues, ESB, disaster recovery, hyperscalability, hypervisor, publishing, monitoring, service discovery, api gateway, design guides) e.g. all that is mentioned in this article.
However, if you cannot go with Microsoft as vendor I agree in the components/guides in this article.
Q: Microservice VS Actor pattern?
In my experience these live in symbiosis, which is supported in Service Fabric, where different actor classes can be built along with microservices (StatelessActor, StatefulService, StatefulActor) and as the latter class implied you dont need databases since state can be persistent in an Actor or Service
– Have you evaluated SF and what’s your thoughts?
Personally I like both, I prefer the Apache ecosystem since no vendor lock, and more mature tech as mentioned in the article since SF was born 2015-11 as preview and have had a lot of breaking changes, bugs on the way. Today it’s pretty stable though, but there might be surprises.
LikeLiked by 1 person
I was recommended this website by my cousin. I’m not
sure whether this post is written by him as no one else know such detailed
about my trouble. You’re amazing! Thanks!
LikeLiked by 1 person
I agree with you, Microsoft fabric is pretty nice, PaaS systems are generally very opinionated in how the applications should behave and work with each other and ties you down (practically) to specific components. This works for a lot of scenarios and doesnt for the rest of them, I suppose if you don’t mind spending time moving away from it at some point from it when you have a need that the PaaS does not support it should be good. This however, is a choice based upon the situation. As a disclaimer I must also add that my knowledge of Microsoft fabric is high level and devoid of practical use, so I might be completely off track :)
LikeLike
Hey! This is my first comment here so I just wanted to give a quick shout out and say I
truly enjoy reading your posts. Can you suggest any
other blogs/websites/forums that cover the same topics?
Thanks!
LikeLike
I generally follow AWS official blog @ https://aws.amazon.com/blogs/aws/ and for nerdy code related stuff I follow erric lippert @ https://ericlippert.com/, I can’t tell you about the same topics exactly, I try to write what I cannot find in general. I don’t actually earn anything out of this :)
LikeLike
I really like it whenever people get together and share views.
Great website, keep it up!
LikeLiked by 1 person
I’ll immediately grab your rss feed as I can’t in finding your email subscription hyperlink or e-newsletter service.
Do you’ve any? Kindly permit me know so that I may just subscribe.
Thanks.
LikeLike
The subscribe button is on the sidebar if you open in desktop, otherwise it falls below the comments section, just scroll. Thanks.
LikeLike
I have been browsing online more than 3 hours today, yet I never found
any interesting article like yours. It’s pretty worth enough
for me. In my opinion, if all site owners and
bloggers made good content as you did, the web will be much more
useful than ever before.
LikeLiked by 1 person
Very good summary Sumit ! Really useful if someone plans to test the waters first time especially on MSA irrespective of cloud topology.
LikeLiked by 1 person
Pingback: Getting started with writing and debugging AWS Lambda Function with Visual Studio Code | cloudncode
As an addition, gRPC (http://www.grpc.io/) is becoming another protocol of choice for inter-service communication.
LikeLiked by 1 person
Pingback: Why Serverless architecture? | cloudncode
Consuta em 19/09/09. Admissão em: 11 abundância. 2009. https://sexonanet.net/comendo-a-mae-do-amigo/
LikeLike