At Tavisca Solutions we started developing beats a few months ago and as the product discovery went to a stage when we wanted to begin with a fast iterative product which can quickly evolve to MVP (minimum viable product) stage we were faced with a rare opportunity. Every time we start a new product we have the opportunity to choose the most evolved technology of the time best suited to the nature of the product.
In this blog I am going to talk about what questions we faced and ultimately how we came down to choosing the serverless architecture for our product (yeah, this is not a mystery blog). Ideally, you should know a little about microservices before reading this article, if you don’t know much in that area, I recommend reading this article of mine first.
What is serverless exactly?
People who hear ‘serverless’ the first time normally have two reactions in my experience:
- umm.. Where does the code run?
- I want to beat up the person who coined the term
serverless, there is no such thing and it just confuses others. - I like my servers, it gives me control.
- sooo…where does the code run?
All good statements of course, let me try to define serverless in my own words:
Serverless architecture is one where the design depends entirely on
third party services where the code runs in ephemeral containers using
functions as a service (FaaS) calling back-end as a service (BaaS) for
data storage needs.
A colleague pointed out that the above statement looks like its copied from Martin Fowlers definition of the same, I assure you, I hadn’t read it till he showed me.
Functions as a service (FaaS)
FaaS is an innovative product of the public cloud model where the economies of scale makes it feasible for the providers to provide a platform where in simple terms, user’s code is executed in containers (e.g. using Docker) and these containers are formed in response to events like an http call to an API gateway or a data packet in a data stream, whatever the cloud provider might support.
My favorite FaaS is AWS Lambda, although Azure provides Azure Functions while Google has Cloud Functions. All of the latter follow the same principle, don't create or maintain a server.
Back-end as a service (BaaS)
Unlike FaaS, BaaS became popular sometime ago in the app developers circuit as they looked for a back end service over the internet which provides features such as data storage (duh), event driven notifications and something that can horizontally scale as their app grows, as a result, BaaS offerings are currently more mature than FaaS and more and more people know about these. AWS has Dynamo DB as its primary offering in this segment, Azure has Cosmos DB while Google has Cloud Datastore.
Let’s visualize what we just talked about:
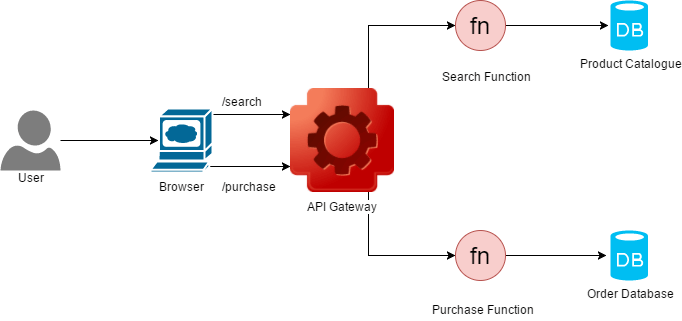
So the browser calls an API gateway, which then uses a container to execute your code which then talks to a DB (BaaS) to get its data, looks familiar right? The high level flow still remains the same of course, with the key difference that in case of the function, the container is created and destroyed based on algorithms used by the FaaS service provider and you have no control over that. I have written a detailed write up about how AWS Lambda works behind the scenes and its best practices and I recommend giving that a read later if you haven’t already.
So there are servers then?
Yup, like surely your common sense already told you whenever you first heard of the term serverless, there are indeed servers that exist. The term serverless in my opinion was coined to relay the fact that you do not create, maintain or even own the servers that are created, in the serverless world servers are created for you based upon need and usage and can change behind the scenes without you even knowing about it.
The above statement is scary, I agree, however, if you have used high quality third party services before especially from the likes of Amazon (AWS), Microsoft (Azure) or Google you know that you can trust them for a up-time at least greater than what you promise with your own servers.
Product-technology fitment
Is Serverless the answer to every problem statement that we have? Certainly not. In order to choose the ‘best’ technology we must first understand the product that we will be using that technology for, otherwise we fall in the trap of choosing the next ‘cool’ thing whether it does justice to the actual business that it is supposed to be catering to or not.
In order to understand Why Serverless we must understand the product requirements in the foreseeable future, what is Serverlesss & understand its nature.
What are the tenets of the Beats product?
Beats is a SaaS offering meant to be used by DMC (Destination management companies) agents or more simplistically travel agents from those not familiar with the Travel industry’s jargon. Here is a 10,000 foot picture of what Beats requires:
- A software being developed via a product development methodology “inspired” by Marty Cagan’s book ‘Inspired’, which superficially speaking the product development cycle will be highly iterative based on the product’s own discovery cycle (market/customer feedback among other things).
- Market research currently puts the pricing of each user license for the offering at 999/- INR (~ USD 15.6), which means the cost of running the offering per user should be significantly lower.
- The product development cycle needs to show significant, sustainable growth at a faster than regular rate till at least we find some market footing.
- The nature of the software will spin out multiple user experiences in the near future such as offline apps for agents working in holiday destinations with questionable internet.
- We are not backed by a billion dollar investor.
What a product manager does not like the engineering team doing?
Anything that is perceived as slowing down product development, chiefly:
1. Maintaining servers manually or writing Chef/Puppet scripts
2. Writing cloud automation scripts / or doing it manually (shudder)
3. Refactoring to make things scalable (handling more users)
4. Non-functional bug fixes
Wherewithal’s of the technology arm of any SaaS offering
- People salaries, high skilled technical staff like developers, devops, QA automation engineers, leads
- Infrastructural costs – cost to run the servers / services, databases and their licenses across environments (dev/qa/stage/prod etc)
- Third party licenses e.g. GitHub private repo’s, MyGet.org (package management), development IDE’s like Visual Studio etc.
- Developer machines
What is the nature of Serverless architecture?
- We don’t own or control barring safety limits for cost, any servers/VM’s/Containers etc
- Most FaaS services where our code will run will allocate one ephemeral (short-lived) container per request to avoid concurrency issues in such a service
- Due to the above two points, code is enforced to be written in a manner which is horizontally scalable across a large number of instances instead of relying on vertical scaling i.e. bigger machines
- You can’t depend on in-memory state of the application, not for a reasonable amount of time anyway like you could in case of permanent or auto scaling VM’s like AWS EC2’s.
- As infrastructural allotment is on incoming request basis, the pricing for both FaaS and BaaS are usually pay as per use basis, If nobody is calling you, FaaS generally runs free, for BaaS you continue to pay whatever you owe for size of the data that is being maintained and allotted throughput for the service
- If you use the serverless framework (get started) which I highly recommend, developers control the infrastructure via code in their microservices
- You normally don’t get to choose CPU, it is allotted at least in case of AWS Lambda w.r.t the RAM that you do get to choose. Serverless functions are not meant to be fast for heavy computing requirements off a single server, however, you can have a more complex design and scale it out to thousands of such functions in parallel and that in fact might achieve more
- It does not take a trivial amount of time for FaaS services to allocate infrastructure for your requests especially in case of spiky traffic scenarios. AWS Lambda takes anywhere between 5-80 ms to do it depending on code size in my experience
- You don’t need to worry about concurrent / multi-threaded scenarios as your infra is running a request per container at any given point in time
Conclusion
Now that we know what the product needs from its technology and what a Serverless architecture would entail, we can conclude the following for the Beats product:
- We need a microservices model to keep pace with fast iterative changes and multiple user interfaces points to those API’s being at REST
- Since Beats is not a millisecond sensitive application, it simply needs dependable and not slow responses
- The lack of cost and more importantly time to create and maintain our own servers goes heavily towards serverless
- Due to the pay-per-use policies of FaaS and BaaS, I can have 24×7 environments up without paying through the nose for them
- Beats does not have any CPU based heavy lifting to do
- Due to less buggy nature of serverless code due to no concurrency scenarios, enforced scalable model etc, we spend less time in non-functional fixes.
- Since with the serverless framework developers create their own infrastructure definition which means less diverse expertise requirements and more importantly developers know exactly what they are building and what its run on
That’s it, I hope I have answered the why serverless? question, I welcome feedback in the comments section, do checkout the tools recommendation for a serverless architecture below.
Tools Recommendation
Infrastructure Creation & Updates
If you are going to go for Serverless, I highly recommend using the serverless framework, I wrote a getting started article on the same which walks you through creating your first serverless application as well.
Serverless CI
AWS CodeBuild and CodePipeline gives you a good alternative to Jenkins without having a server and a nice and cheap pay per use pricing model to boot.
Package Management
MyGet.org is an excellent package management service with built in CI for your packages available.
FaaS
No secret, AWS Lambda is my choice, get started with it.
API Gateway
Necessary to call your FaaS, if you use AWS Lambda, AWS API Gateway is your only option, I am not sure what all works with Google and Microsoft’s counterparts right now.
BaaS
AWS Dynamo DB is an excellent service which by the way also has an excellent caching layer service AWS DAX coming up soon.
If you liked this article, you can choose to follow this blog/subscribe to email alerts (top of sidebar or below comments in mobile) so that you know when any future posts come about.




Pingback: Why Serverless architecture? | Ace Infoway
Pingback: Is AWS Lambda expensive to run? | cloudncode